Introduction to reproducible data analysis with R and Quarto
Open Science for ensuring reproducibility and replicability

The benefits of Open Science for behavioral researchers

Source: The benefits of Open Science
Change your mental model
Source

Output
Source
---
title: "ggplot2 demo"
author: "Norah Jones"
date: "5/22/2021"
format:
html:
fig-width: 8
fig-height: 4
code-fold: true
---
## Air Quality
@fig-airquality further explores the impact of temperature
on ozone level.
```{r}
#| label: fig-airquality
#| fig-cap: Temperature and ozone level.
#| warning: false
library(ggplot2)
ggplot(airquality, aes(Temp, Ozone)) +
geom_point() +
geom_smooth(method = "loess"
)
```Output 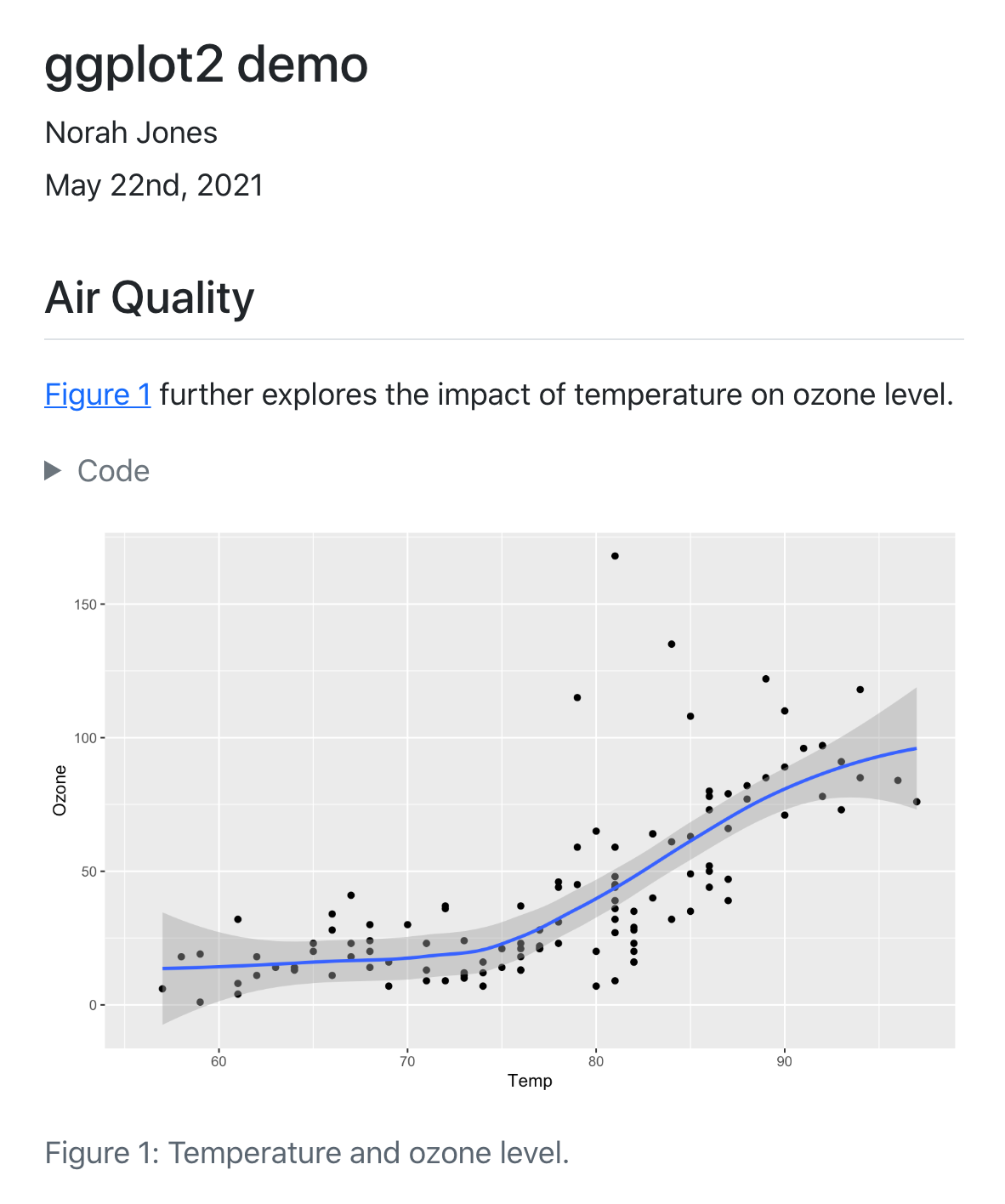
Getting Started with R and RStudio

Create a folder for your R project

Create an R project

Create a Quarto document (report.qmd)

How does Quarto work?

Rendering
Code

Creating a correlation plot

Scatterplot

takk for oppmerksomheten!
